終於要到了尾聲,接下來要介紹的是怎麼去評測RAG
這邊參考了一些文獻,自己整理出的幾項標準與工具!

除了上述,還有許多種的評估指標
CRAG包含4,409個問答組,測試範圍橫跨5大領域,如金融、運動、音樂、電影和百科,另外包含8種問題類型,像是條件式簡單問題、比較型問題、加總型問題等。CRAG可測試2種RAG能力,包括網路搜尋和API串接形式,讓使用者了解自家系統在動態和靜態事實下的檢索、合成與生成能力。
Meta團隊也用CRAG來評估LLM,發現最先進的語言模型準確率只有34%,透過RAG加持可提升到44%。而且,即便是業界先進的系統,在處理動態和複雜查詢時,也只能回答63%的問題且不產生幻覺。Meta希望透過CRAG,來推動問答系統的創新和進步,克服語言模型的幻覺和知識差距。與此同時,CRAG也是Meta今年3月展開的KDD Cup 2024挑戰賽基準,全球已有數千名參賽者來測試、精進自家RAG系統,Meta團隊也會持續擴充CRAG,來推進RAG技術發展。但此技術太新啦,我們這邊就不先進行琢磨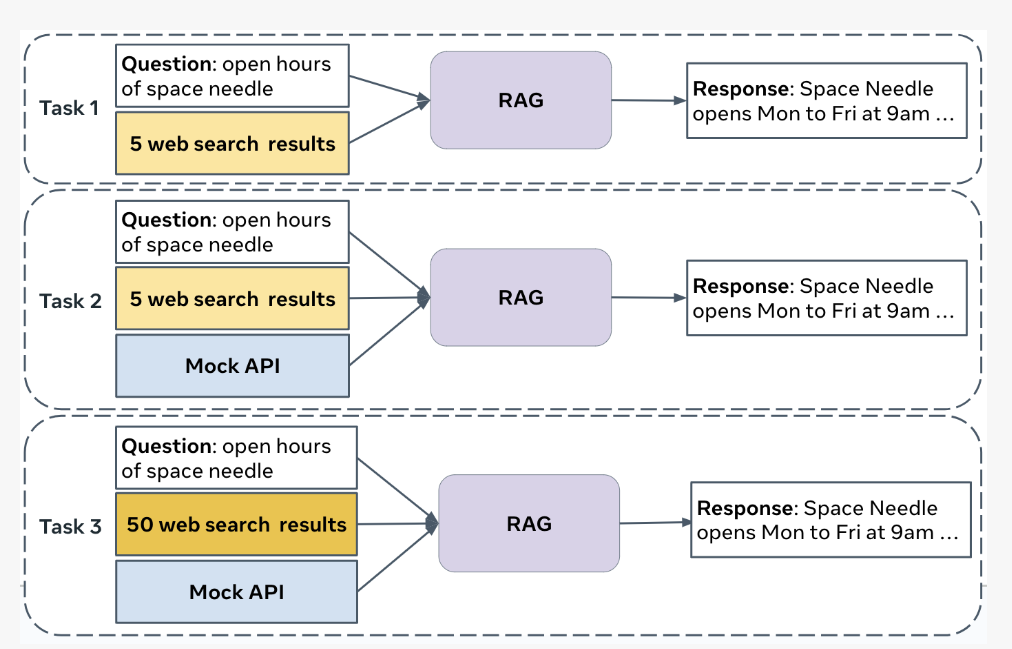
這邊快速介紹Ragas 和 trulens這兩種主流評測RAG的工具:
RAGAS(RAG Assessment System)是一個專門設計來評估RAG系統性能的工具。它提供了多種評估指標,幫助使用者對RAG系統進行全面的分析。以下是RAGAS的一些主要特點:
多維度評估:RAGAS通過多個維度來評估RAG系統的性能,例如回應的語義相似度、回應的流暢度、以及回答的精確性和相關性等。
語義相似度:RAGAS使用語義相似度來評估生成的回答與期望回答之間的相似度,這可以幫助確保系統能夠生成與上下文和問題高度相關的回答。
自動化評估:RAGAS支持自動化的評估流程,這使得大規模的系統測試和調整變得更加容易和高效。
靈活性:RAGAS允許使用者定義自己的評估指標和權重,根據具體的應用場景來調整評估標準。
TruLens是一個開源工具,旨在提供透明度和可信性評估,尤其是針對生成式AI模型。它不僅僅用於RAG系統的評估,也可以用於其他類型的生成式模型。TruLens的設計目的是幫助開發者和使用者理解模型的決策過程,並通過可視化和解釋生成的結果來提高模型的可信性。
以下是TruLens的一些主要特點:
透明度和解釋性:TruLens提供了對生成式模型的內部運作機制的可視化和解釋,幫助使用者理解模型如何得出特定的結果。
可視化工具:TruLens內建了豐富的可視化工具,用來展示模型的推理過程、生成結果與輸入之間的關聯性,以及模型在不同場景下的表現。
多層次評估:TruLens可以從多個層次來評估生成式模型的性能,包括語義層面、語法層面以及應用層面。
互操作性:TruLens支持多種生成式模型框架,可以方便地與不同的AI開發工具集成,為開發者提供靈活的使用體驗。
社區和開源:TruLens作為開源工具,擁有活躍的社區支持,使用者可以參與到工具的改進中,並分享他們的經驗和最佳實踐。
兩者都可以根據需求用來提升RAG系統的質量和可靠性。
但再下一章節,我這邊將主要針對Ragas來去細談,因為此套件已經有寫好SDK來去方便供測試
而且!而且!
它在Github上的star數量是trulens的3倍,這也是我們考量要點之一XD
所以後來就選擇用Ragas來實作啦!
下一章將詳細介紹Ragas 與提供評測code!

